




In article, we will be seeing how extract feed and posts details using RSS feed for a Hashnode blog. Although we are going to use it for blogs on [Hashnode] it can be used for other feeds as well
What is RSS?
RSS stands for Rich Site Summary or Really Simple Syndication and uses standard web feed formats to publish frequently updated information: blog entries, news headlines, audio, video.
An RSS document (called “feed”, “web feed”, or “channel”) includes full or summarized text, and metadata, like publishing date and author’s name.
With RSS it is possible to distribute up-to-date web content from one web site to thousands of other web sites around the world.
It is written in XML.
The most commonly used elements in RSS feeds are “title”, “link”, “description”, “publication date”, and “entry ID”.
The less commonnly used elements are “image”, “categories”, “enclosures” and “cloud”.
Why use RSS?
RSS was designed to show selected data.
Without RSS, users will have to check your site daily for new updates. This may be too time-consuming for many users. With an RSS feed (RSS is often called a News feed or RSS feed) they can check your site faster using an RSS aggregator (a site or program that gathers and sorts out RSS feeds).
Parsing feeds with Feedparser
Feedparser is a Python library that parses feeds in all known formats, including Atom, RSS, and RDF.
Installing feed parser
pip install feedparser
getting rss feed
blog_feed = feedparser.parse("https://vaibhavkumar.hashnode.dev/rss.xml")
title of feed
blog_feed.feed.title
link of feed
blog_feed.feed.link
number of posts/entries
len(blog_feed.entries)
Each entry in the feed is a dictionary. Use [0] to print the first entry.
print(blog_feed.entries[0].title)
print(blog_feed.entries[0].link)
print(blog_feed.entries[0].author)
print(blog_feed.entries[0].published)
gettings tags and authors
tags = [tag.term for tag in blog_feed.entries[0].tags]
authors= [author.name for author in blog_feed.entries[0].authors]
Other attributes
blog_feed.version
Putting it together
Now use the above code to write a function which takes link of RSS feed and return the details.
def get_posts_details(rss=None):
"""
Take link of rss feed as argument
"""
if rss is not None:
import feedparser
blog_feed = blog_feed = feedparser.parse(rss)
posts = blog_feed.entries
posts_details = {"Blog title" : blog_feed.feed.title,
"Blog link" : blog_feed.feed.link}
post_list = []
for post in posts:
temp = dict()
try:
temp["title"] =post.title
temp["link"] =post.link
temp["author"] =post.author
temp["time_published"] = post.published
temp["tags"] = [tag.term for tag in post.tags]
temp["authors"] = [author.name for author in post.authors]
temp["summary"] = post.summary
except:
pass
post_list.append(temp)
posts_details["posts"] = post_list
return posts_details
else:
return None
Output:
import json
blog_rss = "https://vaibhavkumar.hashnode.dev/rss.xml"
data = get_posts_details(rss = blog_rss)
print(json.dumps(data, indent=2))
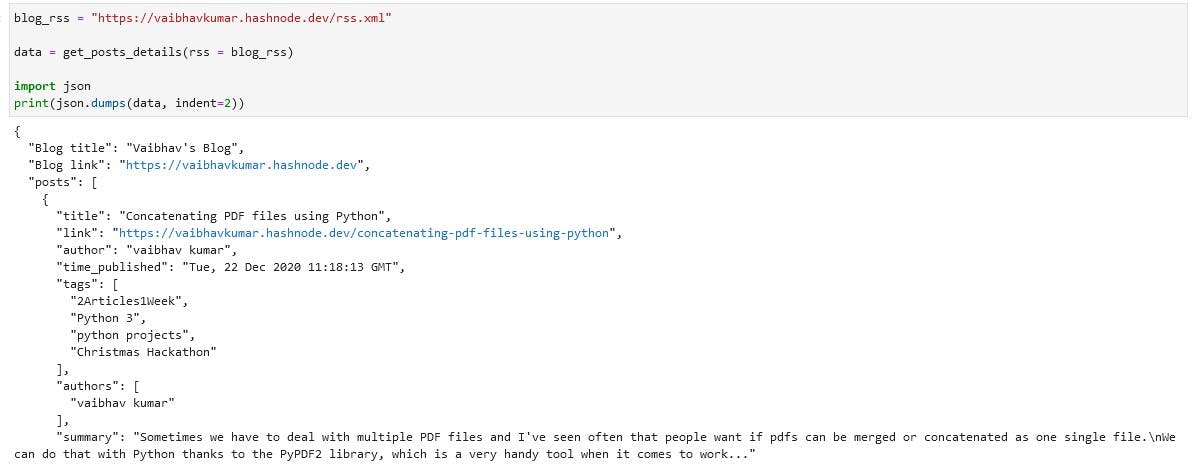
Using this one can quickly get the posts lists, links and other details. Also once we have all the posts links, we can crawl them one by one and scraping details like number of likes, comments on each individual posts.
Also, we can use this to expose the details via JSON based APIs.
Try it, with your own blog's RSS feed link.
Thanks for reading. Do give your suggestions and feedback down in the comments.