


Most of us when think about doing web scraping and HTML parsing using python, we use tools like beautiful-soup, scrapy, regular expressions etc.
In this article, I will show you the basics of web scraping with Requests-HTML library, by Kenneth Reitz.
This library intends to make parsing HTML (e.g. scraping the web) as simple and intuitive as possible.
I will first show the basics of the library and then use it to scrape problems list from HackerRank.
Installing
$ pip install requests-html
We will be using a sample html code for this.
sample.html:
<!doctype html>
<html class="no-js" lang="">
<head>
<title>Test - A Sample Website</title>
<meta charset="utf-8">
<link rel="stylesheet" href="css/normalize.css">
<link rel="stylesheet" href="css/main.css">
</head>
<body>
<h1 id='site_title'>Test Website</h1>
<hr></hr>
<div class="article article-box">
<h2><a href="article_1.html">Article 1 Headline</a></h2>
<p>This is a summary of article 1</p>
</div>
<hr></hr>
<div class="article article-box number">
<h2><a href="article_2.html">Article 2 Headline</a></h2>
<p>This is a summary of article 2</p>
</div>
<hr></hr>
<div id='footer'>
<p>Footer Information</p>
</div>
<script>
var para = document.createElement("p");
var node = document.createTextNode("This is a dynamically generated text.");
para.appendChild(node);
var element = document.getElementById("footer");
element.appendChild(para);
</script>
</body>
</html>
Let's see this in action
from requests_html import HTML # for parsing an html source or code
with open('sample.html') as html_file:
src = html_file.read()
html = HTML(html=src)
print(html.html)
Output:
<!doctype html>
<html class="no-js" lang="">
<head>
<title>Test - A Sample Website</title>
<meta charset="utf-8">
<link rel="stylesheet" href="css/normalize.css">
<link rel="stylesheet" href="css/main.css">
</head>
<body>
<h1 id='site_title'>Test Website</h1>
<hr></hr>
<div class="article article-box">
<h2><a href="article_1.html">Article 1 Headline</a></h2>
<p>This is a summary of article 1</p>
</div>
<hr></hr>
<div class="article article-box number">
<h2><a href="article_2.html">Article 2 Headline</a></h2>
<p>This is a summary of article 2</p>
</div>
<hr></hr>
<div id='footer'>
<p>Footer Information</p>
</div>
<script>
var para = document.createElement("p");
var node = document.createTextNode("This is text generated by JavaScript.");
para.appendChild(node);
var element = document.getElementById("footer");
element.appendChild(para);
</script>
</body>
</html>
.text attribute
print(html.text)
output:
Test - A Sample Website
Test Website
Article 1 Headline
This is a summary of article 1
Article 2 Headline
This is a summary of article 2
Footer Information
var para = document.createElement("p"); var node = document.createTextNode("This is text generated by JavaScript."); para.appendChild(node); var element = document.getElementById("footer"); element.appendChild(para);
finding via css-selectors
match = html.find('title') # finding via css-selectors
print(match)
print(match[0])
print(match[0].html)
print(match[0].text)
output:
[<Element 'title' >]
<Element 'title' >
<title>Test - A Sample Website</title>
Test - A Sample Website
using first=True
match = html.find('title', first=True) # finding via css-selectors
print(match)
print(match.html)
print(match.text)
output:
<Element 'title' >
<title>Test - A Sample Website</title>
Test - A Sample Website
article = html.find('div.article', first=True)
print(article)
print(article.html)
print(article.text)
output:
<Element 'div' class=('article', 'article-box')>
<div class="article article-box">
<h2><a href="article_1.html">Article 1 Headline</a></h2>
<p>This is a summary of article 1</p>
</div>
Article 1 Headline
This is a summary of article 1
article = html.find('div.article', first=True)
headline = article.find('h2', first=True).text
summary = article.find('p', first=True).text
print(headline)
print(summary)
output:
Article 1 Headline
This is a summary of article 1
Looping over list of articles
articles = html.find('div.article') # don't use first=True
for article in articles:
headline = article.find('h2', first=True).text
summary = article.find('p', first=True).text
print(headline)
print(summary)
print()
output:
Article 1 Headline
This is a summary of article 1
Article 2 Headline
This is a summary of article 2
Rendering javascript
html.render()
match = html.find('#footer', first=True)
print(match.html)
When we will use render() first time, it will download chromium driver which is used for rendering.
output:
<div id="footer">
<p>Footer Information</p>
<p> This is a dynamically generated text. </p>
</div>
Sync and Async requests
You can also make asynchronous requests for multiple links using this library. This is helpful when we have multiple links or websites to scrape data.
First see, what is synchronous set of requests. We will make call to httpbin.org/delay for simulating response delay.
import time
from requests_html import HTMLSession
session = HTMLSession()
t1 = time.perf_counter()
r = session.get('https://httpbin.org/delay/1')
response = r.html.url
print(response)
r = session.get('https://httpbin.org/delay/2')
response = r.html.url
print(response)
r = session.get('https://httpbin.org/delay/3')
response = r.html.url
print(response)
t2 = time.perf_counter()
print(f"Synchronous : {t2 - t1} seconds")
output:
https://httpbin.org/delay/1
https://httpbin.org/delay/2
https://httpbin.org/delay/3
Synchronous : 9.493530099999589 seconds
Now, make asynchronous requests
from requests_html import AsyncHTMLSession
async_session = AsyncHTMLSession()
async def get_delay1():
r = await async_session.get('https://httpbin.org/delay/1')
return r
async def get_delay2():
r = await async_session.get('https://httpbin.org/delay/2')
return r
async def get_delay3():
r = await async_session.get('https://httpbin.org/delay/3')
return r
t1 = time.perf_counter()
results = async_session.run(get_delay1, get_delay2, get_delay3)
# Each item in the results list is a response object and can be interacted with as such
# basically makes request for all of them around the same time and then manage results as they comes in
#
for result in results:
response = result.html.url
print(response)
t2 = time.perf_counter()
print(f"ASynchronous : {t2 - t1} seconds")
output:
https://httpbin.org/delay/1
https://httpbin.org/delay/2
https://httpbin.org/delay/3
Asynchronous : 3.376486993 seconds
Scraping Challenges list from HackerRank
Here, I will be scraping problems list from hackerrank. For fetching website data, we have to use HTMLSession class instead of HTML class.
from requests_html import HTMLSession
session = HTMLSession()
url="https://www.hackerrank.com/domains/algorithms?filters%5Bstatus%5D%5B%5D=unsolved&filters%5Bdifficulty%5D%5B%5D=easy&badge_type=problem-solving"
res = session.get(url)
Open the url and inspect the web page for challenge list
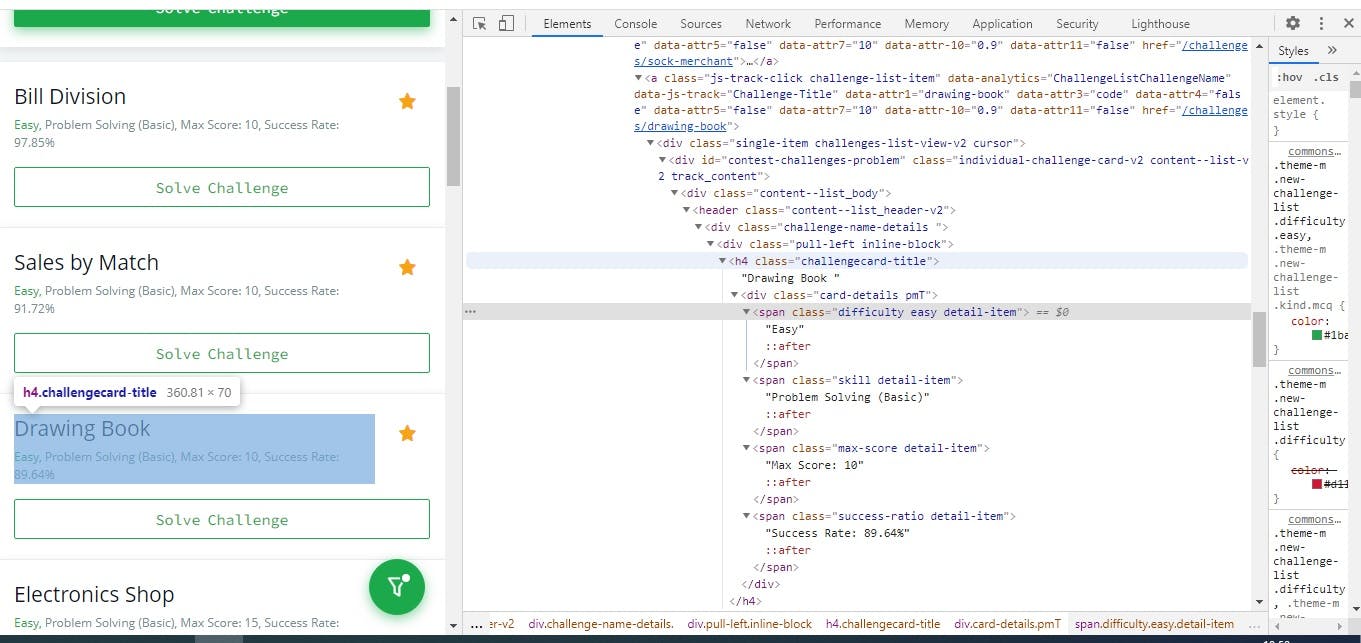
Following are the css-selectors for elements that contains items in challenges list
a.challenge-list-item
div.challenge-name-details
h4.challengecard-title -
div.card-details
span.difficulty.detail-item -
span.skill.detail-item -
span.max-score.detail-item -
span.success-ratio.detail-item -
challenges = res.html.find('a.challenge-list-item')
print(type(challenges[0]))
output:
(requests_html.Element)
root = "https://www.hackerrank.com"
challenges_list = []
for challenge in challenges:
item = {
'link' : (root + challenge.attrs['href']) if challenge.attrs['href'] else "",
'title' : (challenge.find('h4.challengecard-title', first=True).text.split('\n')[0]) if challenge.find('h4.challengecard-title', first=True) else "",
'difficulty' : (challenge.find('span.difficulty', first=True).text) if challenge.find('span.difficulty', first=True) else "",
'skill' : (challenge.find('span.skill', first=True).text) if challenge.find('span.skill', first=True) else "",
'max_score' : (int(challenge.find('span.max-score', first=True).text.split(' ')[-1])) if challenge.find('span.max-score', first=True) else "",
'success_ratio ' : (challenge.find('span.success-ratio', first=True).text.split(' ')[-1]) if challenge.find('span.success-ratio', first=True) else ""
}
challenges_list.append(item)
print(challenges_list[0:5]) # printing first 5 challenges
output:
[{'link': 'https://www.hackerrank.com/challenges/migratory-birds',
'title': 'Migratory Birds',
'difficulty': 'Easy',
'skill': 'Problem Solving (Basic)',
'max_score': 10,
'success_ratio ': '91.24%'},
{'link': 'https://www.hackerrank.com/challenges/day-of-the-programmer',
'title': 'Day of the Programmer',
'difficulty': 'Easy',
'skill': 'Problem Solving (Basic)',
'max_score': 15,
'success_ratio ': '89.40%'},
{'link': 'https://www.hackerrank.com/challenges/bon-appetit',
'title': 'Bill Division',
'difficulty': 'Easy',
'skill': 'Problem Solving (Basic)',
'max_score': 10,
'success_ratio ': '97.85%'},
{'link': 'https://www.hackerrank.com/challenges/sock-merchant',
'title': 'Sales by Match',
'difficulty': 'Easy',
'skill': 'Problem Solving (Basic)',
'max_score': 10,
'success_ratio ': '91.72%'},
{'link': 'https://www.hackerrank.com/challenges/drawing-book',
'title': 'Drawing Book',
'difficulty': 'Easy',
'skill': 'Problem Solving (Basic)',
'max_score': 10,
'success_ratio ': '89.63%'}]
Now, calculate the score that we will get if we solve first ten problems
Max_score = sum([item['max_score'] for item in challenges_list[0:10]])
python(Max_score)
output:
140
Thanks for reading 🙂. Please share any feedbacks down in the comments.
References: